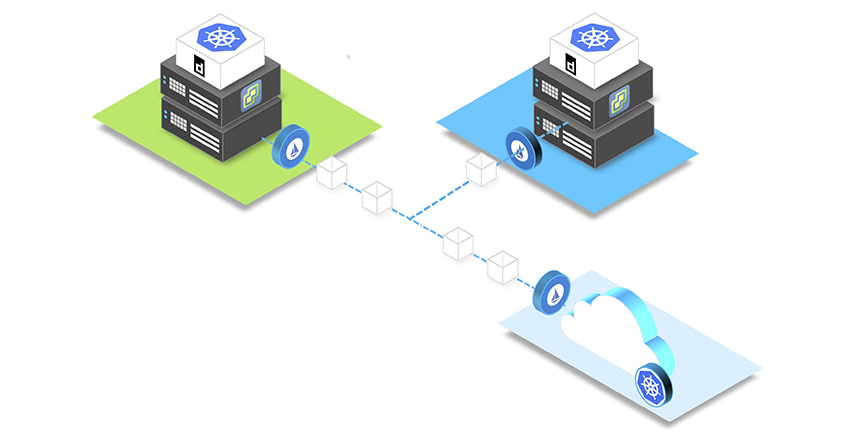
We’ll be taking the opportunity to shed some light on why Containers are the exciting new technology many enterprises see as their future at our upcoming Oreta x Google Cloud event in Melbourne on Tuesday 7th of May. You can read more information here.
But, in the meantime, here’s what we have to say about our experience with Containers, Kubernetes and Service Meshes and how it all fits together. Some common questions we’ll address at our event, in this post and in follow up posts include:
Are Virtual Machines and Containers the same thing?
What are Containers and why are they important?
Are Containers just another form of virtualisation?
Are Containers and Docker the same thing?
Kubernetes: What it is and what it is not?
How Kubernetes can help you deploy and scale your containers and applications as container adoption evolves.
How Microservices and Service Mesh (Istio) pair together for Cloud-Native apps.
Nearly every cloud vendor has plans to evolve to a Container ecosystem.
Google Cloud at their Next ‘19 event in San Francisco has dedicated 46 sessions solely on Hybrid Cloud, Kubernetes, Containers and Service Meshes. Nearly every hardware, software or cloud vendor including Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform, VMware, Red-Hat, Cisco, IBM etc. are heavily invested, have tailored offerings, or have a road map that includes plans on how their products will evolve to cater to the Container ecosystem.
If we look at the Cloud-Native Foundation (CNCF) landscape and follow the trends, Kubernetes, Containers and Service Meshes form the key ingredients for a true Hybrid Cloud solution. There are big bets and predictions that as the Container ecosystem matures, Kubernetes will be widely adopted as “the defacto abstraction layer” mainly due to its strengths in abstracting away the hardware making it easy to run applications (workloads) in a seamless and standardised way on any supported Public Cloud or on-prem infrastructure.
Why is all this important to you?
It’s no secret that infrastructure modernisation has entered the mainstream and the adoption of Containers and Kubernetes is on the rise for Cloud-Native applications. While most organisations have either heard about Cloud-Native and Containers or understand its importance, most struggle with how to get started.
VMware (founded in 1998) were slowing shaping the IT infrastructure landscape, and in 2004 their introduction of ESXi type1 hypervisor opened possibilities that were never imagined. VM virtualisation was in full steam, and at that time too, many dismissed this virtualisation trend as some fad – but we all know how that turned out.
In 2006, AWS on the back of this VM virtualisation (Xen and later KVM) technology changed the landscape of how infrastructure was going to be delivered and consumed and that shift gave rise to true cloud computing; there were many doubters of this trend too.
In 2013, Docker Inc popularised the concept of Containers by taking the lightweight Container runtime and packing it in a way that made the adoption of Containerisation easy. Even today there are many naysayers.
In 2014, Kubernetes was open sourced by Google Cloud, and this is one of the fastest growing open-source projects.
In 2018, Istio was formed to provide “traffic management, service identity and security, policy enforcement and telemetry services” out of the box delivering another level of abstraction. At Google Cloud Next’19 there have been many sessions that show how Istio’s adoption is increasing developer productivity and observability.
All these advancements in hardware abstraction have led to a paradigm shift in the way IT Infrastructure is delivered and consumed. These improvements in infrastructure delivery and modern forms of infrastructure abstraction, right from the early days of Cloud Computing (Infra as code) to Containers (Docker), Container Orchestration (Kubernetes), Service Meshes (Istio), have fundamentally changed the way organisations, including cloud vendors, build and operate systems.
Since kicking off this series on Containers, Google Next ‘19 has come and gone, and boy, was it packed with some fantastic announcements, most supporting the move of Containers into enterprise. We’ll be putting up a ‘post-Google Next’19’ ‘ summary shortly, going into detail on some of these announcements.
For now, we’re let’s get back to helping you understand Containers at a fundamental level and prepare you for understanding how and why they may benefit your organisation.
As always, if you want further information or have any questions, please reach out to us.
What are containers and why are they important?
These days when we hear the word Containers, most people tend to think Docker and picture the famous blue whale while others imagine actual shipping containers.
Either way, you’re not wrong. Speaking about shipping containers, they’re the perfect analogy to explain what Containers are in a technology context.
The common analogy goes like this: shipping containers solved global trade issues by providing a standard unit of packaging that allows goods to be transported securely regardless of the cargo inside. It doesn’t matter how they are transported or which mode of transport they’re on. Containers in IT do something very similar; they package applications into standard units that can be deployed anywhere.
Containers solve the “works on my machine” issues.
Shipping containers didn’t just cut costs. They changed the entire global trade landscape, allowing new players in the trade industry to emerge. The same can be said for Containers in IT, and more importantly Docker Inc or Docker Containers. Containers don’t just cut cost by allowing efficient use of hardware – they change the entire landscape of how software is packaged and shipped.
While this may put things in perspective, it still leaves many open questions such as:
Are Virtual Machines and Containers the same thing?
Are Containers just another form of virtualisation?
What are ‘cgroups’ and ‘namespaces’?
How are Containers different from Virtual Machines?
Are Containers and Docker the same thing?
What is a Container suitable for?
Are Virtual Machine and Containers the same thing?
The term “virtual machine” was coined by Popek and Goldberg, and according to their original definition:
“a virtual machine is an efficient, isolated duplicate of a real computer machine.”
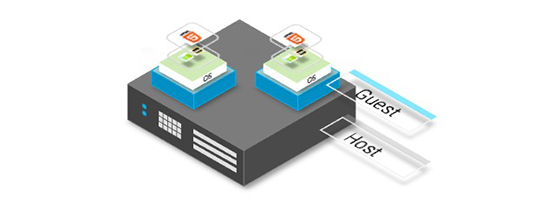
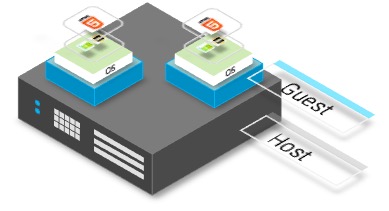
This means the physical computer (the host) can run several virtual computers (guests). These virtual computers are duplicates or emulations of the host. These virtual computers are also known as guests or virtual machines, each of which can imitate different operating systems and hardware platforms. This is depicted in the diagram below where you can see that multiple Guests are on the same physical hardware.
Virtual machines can either be Process Virtual Machines or System Virtual Machines
Process Virtual Machines
Often referred to as Application Virtual Machines, are built to provide an ideal platform to run an intermediate language. A good example is a Java Virtual Machine (JVM) that offers a mechanism to run Java programs as well as programs written in other languages that are also compiled to Java bytecode.
System Virtual Machines
Represents the typical VM as we know it in the infrastructure world. These system Virtual Machines (known colloquially as “VM’s”) emulate separate guest operating systems.
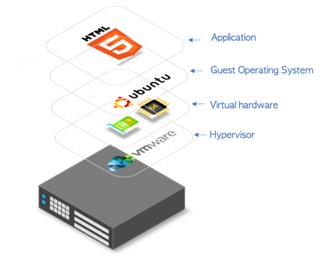
A VM makes it possible to run many separate ‘computers’ on hardware that in reality, is a single computer. In this case, the hypervisor or a VM manager takes over the CPU ring 0 (or the “root mode” in newer CPUs) and intercepts all privileged calls made by guest OS to create an illusion that guest OS has its own hardware.
A visual depiction is shown in the diagram on the right, at the base is the Host computer. Immediately above this is the hypervisor. The hypervisor enables the creation of all the necessary virtualised hardware such as virtual CPU, virtual memory, disk, network interfaces and other IO devices. The virtual machine is then packaged with all the relevant virtualised hardware, a guest kernel that enables communication with the virtual hardware and a guest operating system that hosts the application.
Each guest OS goes through all the process of bootstrapping, loading kernel etc. You can have very tight security, for example, guest OS can’t get full access to host OS or other guests and mess things up.
The question then arises, are Containers just another form of virtualisation?
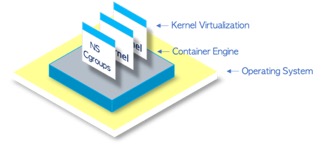
Yes, Containers are just another form of virtualisation. Containers are OS-level virtualisation. Also known as kernel virtualisation whereby the kernel allows the existence of multiple isolated user-space instances called Containers. These Containers may look like real computers from the point of view of programs running in them.
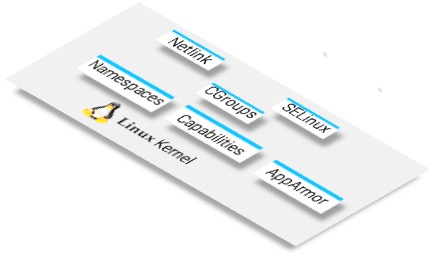
Containers make use of Linux kernel features called control groups (cgroups) and namespaces that allows isolation and control of resource usage.
What are ‘cgroups’ and ‘namespaces’?
cgroups is a Linux kernel feature that makes it possible to control a group or collection of processes. This feature allows it to set resource usage limits on a group of processes. For example, it can control things such as how much CPU, memory, file system cache a group of processes can use.
Linux namespaces is another Linux kernel feature and a fundamental aspect of Linux containers. While it’s not technically part of the cgroups, namespace isolation is a crucial concept where groups of processes are separated such that they cannot “see” resources in other groups.
Now if Containers are just another form of virtualisation, how are Containers different from Virtual Machines?
Let’s elaborate a bit more on namespaces by using a house as an example. A house that has many rooms and let’s imagine a room represents a namespace.
A Linux system starts with a single namespace, used by all processes, This is similar to a house with no rooms, and all the space is available to the people living in the house. Processes can be used to create additional namespaces and attached to different namespaces. Once a group of processes are wrapped in a namespace and controlled with cgroups, they are invisible to processes that run in another namespace. Similarly, people can create new rooms and live in those rooms. However, with the caveat that once you are in a room, you have no visibility to what takes place in other rooms.
By way of example, if we mount a disk in a namespace A, then processes running in namespace B can’t see or access the contents of that disk. Similarly, processes in namespace A can’t access anything in memory that is allocated to namespace B. This provides a kind of isolation such that processes in namespace A can’t see or talk to processes in namespace B.
This is how Containers works; each Container runs in its own namespace but uses exactly the same kernel as all other Containers.
The isolation happens because kernel knows the namespace that was assigned to the process and during API calls, it makes sure that process can only access resources in its own namespace.
By now it should be clear that you don’t run the full-fledged OS in Containers like in VMs. However, you run different distros of an OS because Containers share the same kernel. Since all containers share the same kernel, they are lightweight. Also, unlike VM, you don’t have to pre-allocate a significant chunk of resources (memory, CPU, etc.) to Containers because we’re not running a new copy of an OS. This gives us the ability to spin up significantly number of Containers on one OS than VMs.
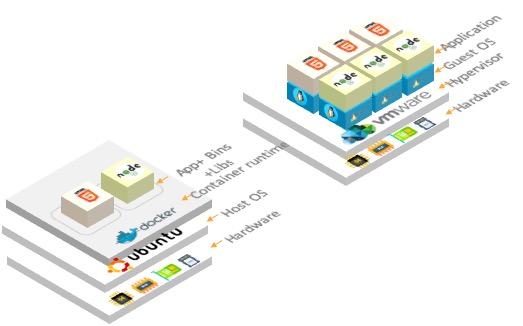
As we have seen, Virtual Machines package virtual hardware, application code and an entire operating system whereas containers only package the code and the essential libraries required to run the code.
Virtual Machines also provide an abstraction layer above the hardware so that a running instance can execute on any server. By contrast, a Container is abstracted away from the underlying operating environment, enabling it to be run just about anywhere: servers, laptops, private-clouds, public clouds, etc.
These two characteristics of Containers free developers to focus on application development, knowing their apps will behave consistently regardless of where they are deployed.
While we are on the topic of Containers, another common question we hear. Are Containers and Docker the same thing?
No, they are not. Docker can mean three different things:
Docker Inc, the reference to the company that created docker
It can be the container runtime and orchestration engine or
It can be a reference to the open source Docker Moby project
While Docker Inc, popularised the concept of Containers by taking the lightweight Container runtime and packing it in a way that made the adoption of Containerisation easy, you can run Containers without Docker. There are several alternatives; the most popular is LXC, with subtle differences, which we won’t cover in this blog.
Considering Docker is very popular, here is a quick overview. The initial release of Docker consisted of two major components: the docker daemon and LXC. LXC provided the fundamental building blocks of containers that existed within the Linux kernel this includes things like namespaces and cgrougs. Later LXC was replaced by Libcontainer, that made docker platform agnostic. Docker became more modular and broken down into smaller, more specialized tools, and the result was a pluggable architecture. The main components of Docker are:
Runc: The OCI implementation of the container-runtime specification, it’s a lightweight wrapper for libcontainer, and its sole purpose in life is to create containers.
Containers: Part of the refactor, all the parts responsible for managing the lifecycle of the container was ripped out of docker daemon and put into containers. Containers are accountable for managing the lifecycle of containers, including starting, stopping, pausing and deleting them. It sits between the docker daemon and runs at the OCI layer. It is also responsible for the management of images (push and pull)
Shim: The implementation of daemon-less Containers, it is used to decouple containers. When a new container is created Containers forks an instance of runs for each new container and hands it over to Shim.
Containers offer a logical packaging mechanism in which applications can be abstracted from the environment in which they run. This decoupling allows container-based applications to be deployed quickly and consistently, regardless of whether the target environment is a private data centre, the public cloud, or even a developer’s laptop.
Containerisation provides a clean separation of concerns, as developers focus on their application logic and dependencies, while IT operations teams can focus on deployment and management without bothering with application details such as specific software versions and configurations specific to the app.
The Container serves as a self-isolated unit that can run anywhere that supports it. Moreover, in each of these instances, the container itself will be identical. Thus you can be sure the container you built on your laptop will also run on the company’s servers.
The Container also acts as a standardised unit of work or computer. A common paradigm is for each container to run a single web server, a single shard of a database, or a single Spark worker, etc. Then to scale an application, you need to scale the number of containers.
In this paradigm, each Container is given a fixed resource configuration (CPU, RAM, # of threads, etc.) and scaling the application requires scaling just the number of containers instead of the individual resource primitives. This provides a much easier abstraction for engineers when applications need to be scaled up or down.
Containers also serve as a great tool to implement the microservice architecture, where each microservice is just a set of co-operating containers. For example, the Redis micro service can be implemented with a single master container and multiple slave containers.
In the next post, we will go into detail on Hybrid container deployments and understanding how you can run across both on-premise and public cloud(s) to meet your end-user / customer demands. We will cover how to simplify your management in these hybrid/multi-cloud deployments, even when your internal skill sets may still be developing.
Thanks for reading, we appreciate any feedback you may have on this topic and the content level in general. So if you have something you’d like to say, please feel free to drop us a line here.
On September 18th – 19th, the Google Cloud Summit 2019 will be held at the International Convention Centre (ICC), Sydney. Will you be there? In 2018, Oreta showcased the hybrid container deployment models using Google Kubernetes engine, Istio and Cisco container platforms. In 2019, we are taking it one step further.
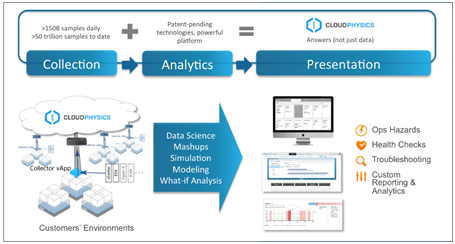
At this year’s Summit, we will take you on a Journey to Cloud using live demonstrations and real-life scenarios. You will learn about the power of Cloud Physics – a tool that provides extraordinary visibility into your environment and helps remove the blockers to successfully adopt Google Cloud.
You will be able to see first-hand the simplicity and flexibility of using various migration tools, and how virtual machine workloads can move from another cloud, or on-premise VMware based infrastructure, to the Google Cloud Platform (GCP).
Furthermore, you’ll have the opportunity to observe how services, such as Migrate for Compute Engine and Migrate for Anthos, work to move and convert your workloads from your on-premise environment directly into containers in Google Kubernetes Engine (GKE).
Diagram 1: Journey to Cloud – Assessing, Migrating and Modernising
In this blog, we provide a brief overview of what our focus points will be at the Summit and answer several important questions about migration, including:- Why do we need to understand the reasons for migration? – Why do we need to quantify the cost of a new cloud model? – What tools can we use to review the current and future state of every workload within our business, and ensure we make the most suitable and cost-effective decisions regarding what models and features we require? – How can we continue to modernise our IT landscape?
Why do we need to migrate?
Google Cloud Platform (GCP) offers low costs and unique features that make migration very compelling. Unfortunately, many of the processes, calculations, and how-tos are beyond the experience of most organisations. It often is not as simple as a “lift-and-shift” effort. To truly succeed at migration, we need to step back and clearly define and evaluate the purpose and process.
Diagram 2: Migration is not as simple as just a ‘Lift and Shift’.
Assessing: Discover / Assess / Plan Design
Before beginning the assessment process, we need to understand ‘Why’ we are migrating and ask ourselves the following questions:
1. What do we think cloud computing can offer the business, that we do not have today?
2. Do we want to improve our flexibility, including the ability to expand and contract instantaneously without incurring increased capital expenditure for new resources?
3. Do we need particular services that cannot be implemented on-site, such as disaster recovery, security or application mobility?
4. Is the goal to differentiate the business to gain a competitive advantage, or to focus more on collaborative integrated solutions with preferred partners?
Before deciding which workloads should move to the cloud, we need to determine the purpose of the migration and what we want to achieve by this transformation. In fact, defining the purpose of the migration can be as critical as designing the actual platform.
Diagram 3: Defining the purpose of the migration can be as critical as designing the platform.
Migrating: Quantify the cost of the new cloud model.
After you have defined the purpose of migration, you would typically want to quantify the cost implications of the new cloud model. The three main factors you will need to consider are:
1. Differing configurations, commitments, and choices of which workloads to move,
2. The process by which we select and exclude workloads in cloud migration,
3. What workloads will migrate to the new cloud? Selecting all workloads in an environment is typically not a wise choice, especially as the effort to quantify costs per VM can be daunting.
Without a solid tool to review the current and future state of every workload, most organisations are not equipped to make the most cost-effective decisions on what models and features are best to use.
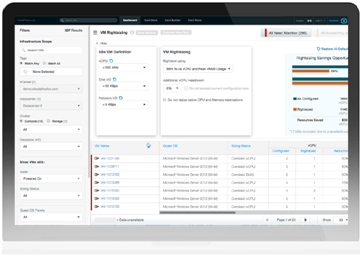
At Oreta, we use CloudPhysics to select and exclude workloads. The tool enables visibility into all workloads and includes tagging and exclusion functionality. CloudPhysics also gives you the ability to conduct rightsizing, which can add further savings to the process.
Diagram 4: Cloud Physics is a solid tool to review the current and future state of every workload.
Modernising: A top priority in the IT landscape
For businesses across the world, the ability to modernise their IT landscape is a top priority. As a Google premier partner, Oreta has been working with Google’s migration tools to support customers during their ‘Journey to Cloud’, and achieve their objectives in modernising.
At the summit, we will demonstrate several of Google’s latest offerings including;
1. “Migrate for Anthos”, which enables you to take VMs from on-prem, or Google Compute Engine, and move them directly into containers running in Google Kubernetes Engine (GKE),
Diagram 5: Migrate to Anthos’ is one of Google’s latest migration tools Oreta will be showcasing.
2. “Migrate for compute engine”, which allows you to take your application running in VM’s from on-prem to Google Compute Engine, and caters for;
– Fast and easy validation before you migrate, – A safety net by fast on-premises rollback, – Migration waves to execute bulk migration.
Diagram 6: Migrate to Compute Engine’ is one of Google’s latest migration tools Oreta will be demonstrating.
The Google Cloud Summit in 2019 is set to be better than ever. We hope this short glimpse into what Oreta will be showcasing has inspired you to come along, learn about some of Google’s latest offerings and enjoy our live demonstrations.
If you haven’t registered to attend the Summit yet it’s not too late. Simply register here.
If you are unable to attend the Summit but would like more information on the above, or any other service Oreta provides, please phone 13000 Oreta or contact us here.
Cloud – we’ve all heard of it, and we are probably all using it in some form now – Office 365, Salesforce, MYOB are some of the many Software as a Service (SaaS) products that are “in the cloud” today.
However, there is still some ambiguity over what is cloud computing, how do Public Cloud, Private Cloud and Hybrid Cloud differ, and how secure is it.
We define cloud computing as having the following five attributes: (1) on-demand self-service, (2) broad network access, (3) resource pooling, (4) rapid elasticity, and (5) measured services (pay as you go); for compute, network and storage.
Options in cloud compute solutions have extended to include customer-dedicated solutions, such as HCI (Hyper-Converged Infrastructure), that are modular, elastic and relatively quick to set up – all characteristics of Cloud compute, but are also dedicated and “in house”. However, customer dedicated solutions may lack some other features of Cloud computing. HCI is categorised under the Private Cloud umbrella solution, although it requires some of the self-service portals.
Looking at the abundance of solutions available for businesses today, choosing what the right solution is can be complicated and daunting – but the alternative is worse: stagnation.
Cloud Right, not Cloud First, is therefore imperative. The days of jumping both feet first into Public Cloud, no matter what circumstances, is so yesteryear!
Cloud-First is flexing to Cloud Right. Instead of deploying solutions by blindly following a Cloud-First corporate policy, we now select solutions based on what offers the best overall outcome: Cloud Right.
When you are considering your journey to the cloud, you need to look at your companies’ short, medium, and long term requirements. Asking yourself the following questions is a great starting point:
Is your current platform urgently in need of a refresh?
Do you develop or redevelop solutions in-house?
Do you utilise SaaS offerings?
Do you need or want to have dedicated hardware?
Do you want managed infrastructure or do you want to do it yourself?
How much effort do you want to put into managing your compute?
Are you growing IT?
Is a Capex or Opex billing model preferred?
Are there any regulatory or compliance requirements that need to be met?
What Disaster Recovery requirements exist? How long are backups required to be retained? How quick is it to recover from a backup?
Sometimes finding the answers to these questions can be difficult. Too often, people have their blinkers on and cannot see the trees from the forest. Oreta can help. Oreta can assist your organisation prior, during, and after your journey to the cloud.
During Phase 1, the discovery and assessment stages, Oreta conducts a ’Journey to Cloud’ workshop, where Oreta’s cloud architects use special analytical tools to help answer the questions above, and tailor a plan that will best meet your organisation’s needs.
A plan to proceed to the right cloud can then lead to a Cloud Blueprint, a build and first-mover process which will give you a quick step into the cloud for a low-risk application.
However, during Phase 2, you should consider some of the risks you may encounter, particularly if you have opted to move to a public cloud. A public cloud risks being open to the Internet, not just for you but for the rest of the world. Two critical pillars stand together to protect your public cloud: Security and Network.
Security of your data in the cloud is paramount and complex. Companies run with services from different clouds (e.g. Salesforce and Office 365 and IaaS compute etc). And different services have different security responsibility thresholds – for example, security a SaaS service is different to a cloud SQL PaaS and IaaS compute, let alone if these are from different cloud service providers. To secure your cloud you need to ensure your security policies are enforced consistently and corporate wide. A big challenge. CASB (Cloud Access Security Broker) tools protect your SaaS services and CSPM (Certified Security Project Manager) tools protect your IaaS and PaaS public cloud services. It is vital to configure your organisation’s CASB and CSPM correctly from the start to ensure your compute services are as secure as you believe they are. Incorrect setup of these can give you a false sense of security and lead to catastrophic outcomes.
In recent years, the way networks have been deployed has changed to meet the new cloud compute requirements companies have. Flexible and cheaper internet-based links that are software-defined (SD-WAN) have replaced traditional private Multiprotocol Label Switching (MPLS) networks. SD-WAN enables flexible network options to meet your business requirements. Whether provided by Telstra or NBN, a secure network is still required to ensure only authorised people can connect to your systems. SD-WAN delivers on all of these requirements. Oreta specialises in networks and SD-WAN.
So Oreta is the logical solution when you are seeking a service provider that can cater to all your future compute services’ needs – cloud, network and security.
Oreta specialises in ensuring you adopt the cloud that is right for your organisation, connecting your organisation’s internal users to its compute over secure networks, and securing your cloud provided services from possible breaches.
Oreta’s top priority is always to do what is right for the customer.
Congratulations! You’ve decided to accelerate your cloud journey by adopting hyperconverged technologies. Understandably, the decision forms part of our hybrid cloud strategy and may have been a difficult one to make. But you did it. Now it’s time to hit the ground running.
In this blog, we will provide you with several insights into what to do now and recommendations on what you should consider when deploying HCI technologies. For reference purposes, I will refer to Cisco Hyperflex HCI but, please note the problem statements are similar across most HCI architectures.
Before you travel too far, make sure you engage with a partner or similar organisation which has travelled the road before, taken necessary detours and knows where the speed bumps are – they will tell you it’s not all smooth sailing.
Foundation Platform
Selection Select a data centre provider that supports your SLA and business requirements. Consider appointing a broker of cloud services so that you can innovate and connect quickly to the ecosystem of cloud service providers. It is essential to have low latency secure connections. Equinix with its EQ Cloud Exchange has a great offering.
Design and Sizing Traditionally, you were able to scale-out storage and compute separately. With HCI, the storage network and compute are tied to a node. Cisco offers a compute-only node, but for storage it comes with compute – so how do you cater for growth? Decide on the size of the node you require to support your current requirements now and for the next 12 months, while providing the flexibility to add additional ram and storage modules when or if required. Note: For HCI, this must be balanced across all nodes.
Licensing Requirements Consider your Hypervisor, OS, Application and Database licensing requirements which may be tied to your processors or nodes. The cost analysis becomes a balancing act between nodes, CPU, RAM, storage and licencing, which should not be underestimated.
Replication Factor With storage, you have a new paradigm where resiliency is managed by replication across nodes. The recommended replication factor is 3, which provides you with the flexibility to drop nodes for patching while retaining resiliency. You may elect for a DR site to have RF2 as a cost saving. Also, consider the deduplication and compression efficiencies you will get.
Solid State Device (SSD) With the cost of SSD, you may prefer to store all your data onto a SSD or have a hybrid with a spinning disc. If you have VDI or demanding databasesthen SSD is the answer.
Rack size Ensure your rack size supports the scale-out additional nodes. When finalising the sizing, remember that HCI has management overheads that you need to take into account when determining what you receive as usable for CPU, RAM and storage.
Storage options Consider partnering with a service provider for boost capacity or long-term archive storage. Telstra Vintage Storage is an excellent product to use for this or maximise leverage to public cloud.
Management Tools Will you use a traditional approach, with Hyper V or VMware, or a cloud-native approach which can support Cisco’s Hyperflex application or Google’s Anthos platform? When you decide on the hypervisor and management tools you will use, consider the skill sets of those who are responsible for managing the environment and what applications will need to be deployed on the platform.
Other foundational considerations:
The other foundational design requirements to be considered depends on where you are moving from. The following items may already be part of your criteria or need to be added;
Network Connectivity
How will your users connect to the platform? Do you need additional core switches, copper or fibre cabling or networking components, e.g. MPLS, SD-WAN, Dark Fibre, Cloud Exchange, QoS, WAN optmisation, Load Balancers, DNS or Public IP Address requirements.
Do you require physical or virtual appliances? What FW services do you require – e.g. Palo Alto, Checkpoint, etc.
Service Provider
Do you require DDOS, IPS/IDS? Then you need to consider a service provider – e.g. Telstra.
DR solution
Do you require a DR solution? If so, what are your RPO and RTO requirements which may affect your DR architecture?
Architecture
What replication technology and orchestration tools do you require – e.g. Is it a mirror HCI or replication to Azure? Your application and database architecture will also drive the solution. Therefore, you may want to leverage the native HCI replication tools with 5 min RPO or high availability groups with active database architectures for near real-time RPO and RTO.
You may want to leverage the public cloud with near real-time replication with tools such as Veeam and ASR.
Back up
Do you need a backup solution – e.g. Cohesity or Veeam? You will need to consider backing up data sizes. The rate of change will determine whether a dedupe appliance, such as Cohesity, is necessary. These days tools allow you to archive to archive to low-cost blob storages in public cloud, such as Google and Azure, rather than traditional tape. Alternatively, you can buy a ‘Backup as a Service’ (BaaS) – e.g. Telstra BaaS has a 7-year backup product. However, if you change your backup service, it is important that you consider how you will restore from previous archives.
Bill of Materials
Too often the delivery of the bill of materials is underestimated. You need to factor in the ‘random uncontrollable impacts’ that may occur. For example, COVID-19 has delayed manufacturing in China. Average times of manufacturing certain products has increased from several days to 2-6 weeks.
Many organisations are looking to move up the stack to focus on high-value activities innovating for business. HCI simplifies the stack for management and enables this to happen. However, before you deploy HCI make sure you ask yourself;
What support do you require?
Who will manage the foundational platform?
Do you need 24 x 7 or 8 x 5 support?
Oreta in partnership with CIsco can provide organisations with a managed service which can wrap over their platform and provide a highly resilient private cloud.
Without leveraging a cloud provider, it can take a further 4-6 weeks to move up the stack. Once the HCI kit arrives, you need to rack and stack, build the platform, configure and install the hypervisor, harden and test before you can hand it over to support.
Next step – Migrating your workloads
Now you have completed your HCI foundational design, ordered and installed it, you are ready to mitigate your workloads onto the platform.
Finally, if you are on-premise, you may have to consider;
Legacy architectures that may need to be transformed – e.g. RDM for your databases
Windows OS versions or DB versions that need upgrading to support new licencing models for the platform, etc.
Public IP addresses, if you are utilising them.
Acceptable outage windows for your business so you can determine what migration approaches and tooling are the best fit.