Since kicking off this series on Containers, Google Next ‘19 has come and gone, and boy, was it packed with some fantastic announcements, most supporting the move of Containers into enterprise. We’ll be putting up a ‘post-Google Next’19’ ‘ summary shortly, going into detail on some of these announcements.
For now, we’re let’s get back to helping you understand Containers at a fundamental level and prepare you for understanding how and why they may benefit your organisation.
As always, if you want further information or have any questions, please reach out to us.
What are containers and why are they important?
These days when we hear the word Containers, most people tend to think Docker and picture the famous blue whale while others imagine actual shipping containers.
Either way, you’re not wrong. Speaking about shipping containers, they’re the perfect analogy to explain what Containers are in a technology context.
The common analogy goes like this: shipping containers solved global trade issues by providing a standard unit of packaging that allows goods to be transported securely regardless of the cargo inside. It doesn’t matter how they are transported or which mode of transport they’re on. Containers in IT do something very similar; they package applications into standard units that can be deployed anywhere.
Containers solve the “works on my machine” issues.
Shipping containers didn’t just cut costs. They changed the entire global trade landscape, allowing new players in the trade industry to emerge. The same can be said for Containers in IT, and more importantly Docker Inc or Docker Containers. Containers don’t just cut cost by allowing efficient use of hardware – they change the entire landscape of how software is packaged and shipped.
While this may put things in perspective, it still leaves many open questions such as:
- Are Virtual Machines and Containers the same thing?
- Are Containers just another form of virtualisation?
- What are ‘cgroups’ and ‘namespaces’?
- How are Containers different from Virtual Machines?
- Are Containers and Docker the same thing?
- What is a Container suitable for?
Are Virtual Machine and Containers the same thing?
The term “virtual machine” was coined by Popek and Goldberg, and according to their original definition:
“a virtual machine is an efficient, isolated duplicate of a real computer machine.”
This means the physical computer (the host) can run several virtual computers (guests). These virtual computers are duplicates or emulations of the host. These virtual computers are also known as guests or virtual machines, each of which can imitate different operating systems and hardware platforms. This is depicted in the diagram below where you can see that multiple Guests are on the same physical hardware.
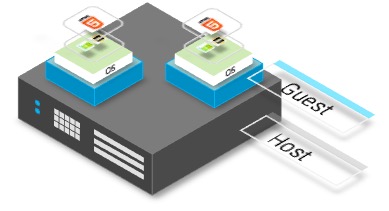
Virtual machines can either be Process Virtual Machines or System Virtual Machines
Process Virtual Machines
Often referred to as Application Virtual Machines, are built to provide an ideal platform to run an intermediate language. A good example is a Java Virtual Machine (JVM) that offers a mechanism to run Java programs as well as programs written in other languages that are also compiled to Java bytecode.
System Virtual Machines
Represents the typical VM as we know it in the infrastructure world. These system Virtual Machines (known colloquially as “VM’s”) emulate separate guest operating systems.
A VM makes it possible to run many separate ‘computers’ on hardware that in reality, is a single computer. In this case, the hypervisor or a VM manager takes over the CPU ring 0 (or the “root mode” in newer CPUs) and intercepts all privileged calls made by guest OS to create an illusion that guest OS has its own hardware.
A visual depiction is shown in the diagram on the right, at the base is the Host computer. Immediately above this is the hypervisor. The hypervisor enables the creation of all the necessary virtualised hardware such as virtual CPU, virtual memory, disk, network interfaces and other IO devices. The virtual machine is then packaged with all the relevant virtualised hardware, a guest kernel that enables communication with the virtual hardware and a guest operating system that hosts the application.
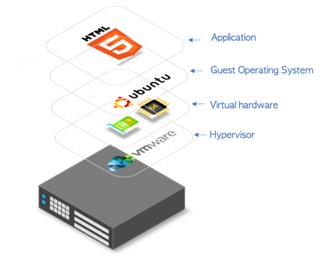
Each guest OS goes through all the process of bootstrapping, loading kernel etc. You can have very tight security, for example, guest OS can’t get full access to host OS or other guests and mess things up.
The question then arises, are Containers just another form of virtualisation?
Yes, Containers are just another form of virtualisation. Containers are OS-level virtualisation. Also known as kernel virtualisation whereby the kernel allows the existence of multiple isolated user-space instances called Containers. These Containers may look like real computers from the point of view of programs running in them.
Containers make use of Linux kernel features called control groups (cgroups) and namespaces that allows isolation and control of resource usage.
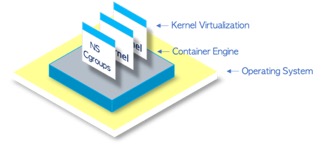

What are ‘cgroups’ and ‘namespaces’?
cgroups is a Linux kernel feature that makes it possible to control a group or collection of processes. This feature allows it to set resource usage limits on a group of processes. For example, it can control things such as how much CPU, memory, file system cache a group of processes can use.
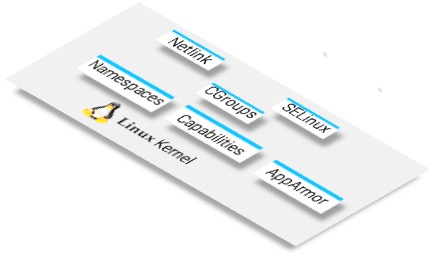
Linux namespaces is another Linux kernel feature and a fundamental aspect of Linux containers. While it’s not technically part of the cgroups, namespace isolation is a crucial concept where groups of processes are separated such that they cannot “see” resources in other groups.
Now if Containers are just another form of virtualisation, how are Containers different from Virtual Machines?
Let’s elaborate a bit more on namespaces by using a house as an example. A house that has many rooms and let’s imagine a room represents a namespace.
A Linux system starts with a single namespace, used by all processes, This is similar to a house with no rooms, and all the space is available to the people living in the house. Processes can be used to create additional namespaces and attached to different namespaces. Once a group of processes are wrapped in a namespace and controlled with cgroups, they are invisible to processes that run in another namespace. Similarly, people can create new rooms and live in those rooms. However, with the caveat that once you are in a room, you have no visibility to what takes place in other rooms.
By way of example, if we mount a disk in a namespace A, then processes running in namespace B can’t see or access the contents of that disk. Similarly, processes in namespace A can’t access anything in memory that is allocated to namespace B. This provides a kind of isolation such that processes in namespace A can’t see or talk to processes in namespace B.
This is how Containers works; each Container runs in its own namespace but uses exactly the same kernel as all other Containers.
The isolation happens because kernel knows the namespace that was assigned to the process and during API calls, it makes sure that process can only access resources in its own namespace.
By now it should be clear that you don’t run the full-fledged OS in Containers like in VMs. However, you run different distros of an OS because Containers share the same kernel. Since all containers share the same kernel, they are lightweight. Also, unlike VM, you don’t have to pre-allocate a significant chunk of resources (memory, CPU, etc.) to Containers because we’re not running a new copy of an OS. This gives us the ability to spin up significantly number of Containers on one OS than VMs.
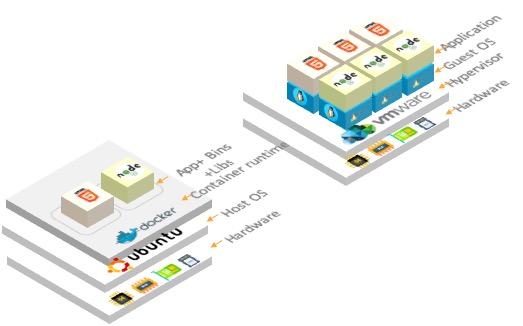
As we have seen, Virtual Machines package virtual hardware, application code and an entire operating system whereas containers only package the code and the essential libraries required to run the code.
Virtual Machines also provide an abstraction layer above the hardware so that a running instance can execute on any server. By contrast, a Container is abstracted away from the underlying operating environment, enabling it to be run just about anywhere: servers, laptops, private-clouds, public clouds, etc.
These two characteristics of Containers free developers to focus on application development, knowing their apps will behave consistently regardless of where they are deployed.
While we are on the topic of Containers, another common question we hear. Are Containers and Docker the same thing?
No, they are not. Docker can mean three different things:
- Docker Inc, the reference to the company that created docker
- It can be the container runtime and orchestration engine or
- It can be a reference to the open source Docker Moby project
While Docker Inc, popularised the concept of Containers by taking the lightweight Container runtime and packing it in a way that made the adoption of Containerisation easy, you can run Containers without Docker. There are several alternatives; the most popular is LXC, with subtle differences, which we won’t cover in this blog.
Considering Docker is very popular, here is a quick overview. The initial release of Docker consisted of two major components: the docker daemon and LXC. LXC provided the fundamental building blocks of containers that existed within the Linux kernel this includes things like namespaces and cgrougs. Later LXC was replaced by Libcontainer, that made docker platform agnostic. Docker became more modular and broken down into smaller, more specialized tools, and the result was a pluggable architecture. The main components of Docker are:
Runc: The OCI implementation of the container-runtime specification, it’s a lightweight wrapper for libcontainer, and its sole purpose in life is to create containers.
Containers: Part of the refactor, all the parts responsible for managing the lifecycle of the container was ripped out of docker daemon and put into containers. Containers are accountable for managing the lifecycle of containers, including starting, stopping, pausing and deleting them. It sits between the docker daemon and runs at the OCI layer. It is also responsible for the management of images (push and pull)
Shim: The implementation of daemon-less Containers, it is used to decouple containers. When a new container is created Containers forks an instance of runs for each new container and hands it over to Shim.
- Containers offer a logical packaging mechanism in which applications can be abstracted from the environment in which they run. This decoupling allows container-based applications to be deployed quickly and consistently, regardless of whether the target environment is a private data centre, the public cloud, or even a developer’s laptop.
- Containerisation provides a clean separation of concerns, as developers focus on their application logic and dependencies, while IT operations teams can focus on deployment and management without bothering with application details such as specific software versions and configurations specific to the app.
- The Container serves as a self-isolated unit that can run anywhere that supports it. Moreover, in each of these instances, the container itself will be identical. Thus you can be sure the container you built on your laptop will also run on the company’s servers.
- The Container also acts as a standardised unit of work or computer. A common paradigm is for each container to run a single web server, a single shard of a database, or a single Spark worker, etc. Then to scale an application, you need to scale the number of containers.
- In this paradigm, each Container is given a fixed resource configuration (CPU, RAM, # of threads, etc.) and scaling the application requires scaling just the number of containers instead of the individual resource primitives. This provides a much easier abstraction for engineers when applications need to be scaled up or down.
- Containers also serve as a great tool to implement the microservice architecture, where each microservice is just a set of co-operating containers. For example, the Redis micro service can be implemented with a single master container and multiple slave containers.
- In the next post, we will go into detail on Hybrid container deployments and understanding how you can run across both on-premise and public cloud(s) to meet your end-user / customer demands. We will cover how to simplify your management in these hybrid/multi-cloud deployments, even when your internal skill sets may still be developing.
Thanks for reading, we appreciate any feedback you may have on this topic and the content level in general. So if you have something you’d like to say, please feel free to drop us a line here.